MySql-Innodb-Cluster简介及安装
MySQL InnoDB Cluster
简介
MySQL的高可用架构无论是社区还是官方,一直在技术上进行探索,这么多年提出了多种解决方案,比如
MMM,MHA,NDB Cluster,Galera Cluster,InnoDB Cluster, 腾讯的PhxSQL,MySQL Fabric,aliSQL。MySQL官方在2017年4月推出了一套完整的、高可用的Mysql解决方案 - MySQL InnoDB Cluster, 即一组MySQL服务器可以配置为一个MySQL集群。在默认的单主节点模式下,集群服务器具有一个读写主节点和多个只读辅节点。辅助服务器是主服务器的副本。客户端应用程序通过MySQL Router连接到主服务程序。如果主服务连接失败,则次要的节点自动提升为主节点,MySQL Router请求到新的主节点。InnoDB Cluster不提供NDB Cluster支持。
分布式MySQL之InnoDB和NDB
分布式MySQL主要有InnoDB和NDB模式, NDB是基于集群的引擎-数据被自动切分并复制到数个机器上(数据节点), 适合于那些需要极高查询性能和高可用性的应用, 原来是为爱立信的电信应用设计的。 NDB提供了高达99.999%的可靠性,在读操作多的应用中表现优异。 对于有很多并发写操作的应用, 还是推荐用InnoDB。
特性
集成易用
MySQL InnoDB集群紧密集成了MySQL Servers with Group Replication,MySQL Router,和MySQL Shell,所以不必依赖于外部工具,脚本或其他部件。 另外它利用了现有的MySQL特性,如:InnoDB, GTIDs, binary logs, multi-threaded slave execution, multi-source replication and Performance Schema。可以在五分钟内利用MySQL Shell中的脚本化的管理API来创建及管理MySQL集群。使用组复制的mysql server HA
组复制提供了内置的组成员管理、数据一致性保证、冲突检测和处理、节点故障检测和数据库故障转移相关操作的本地高可用性,无需人工干预或自定义工具。组复制同时实现了带自动选主的单主模式及任意更新的多主模式。通过使用一个强大的新的组通信系统,它提供了流行的Paxos算法的内部实现,来自动协调数据复制、一致性、membership。这提供了使MySQL数据库高度可用所需的所有内置机制。弹性
通过组复制,一组服务器协调在一起形成一个组。组成员是动态的,服务器可以自愿或强制的地离开及随时加入。组将根据需要自动重新配置自己,并确保任何加入成员与组同步。这样就可以方便地在需要时快速地调整数据库的总容量。故障检测
组复制实现了一个分布式故障检测器来查找并报告failed或不再参与组的服务器,组中剩余成员将重新配置。容错
组复制基于流行的Paxos分布式算法来提供服务器之间的分布式协调。为了使一个小组继续发挥作用,它要求大多数成员在线,并就每一个变化达成协议。这允许MySQL数据库在发生故障时安全地继续操作,而无需人工干预,不存在数据丢失或数据损坏的风险。自愈
如果一个服务器加入该组,它将自动将其状态与现有成员同步。如果服务器离开该组,例如它被取下来进行维护,剩下的服务器将看到它已离开,并将自动重新配置组。当服务器后重新加入组,它会自动重新与组同步。监测
MySQL Enterprise Monitor 3.4及以后的版本全面支持组复制;监控每个节点的配置,健康,和性能。并且提供最佳实践建议和提醒,以及易于理解的可视化工具,允许您轻松地监控和管理您的组复制和InnoDB集群。通过MySQL Router为mysql客户机应用程序实现HA
MySQL的路由器允许您轻松迁移您的独立的MySQL实例到本地分布式高可用集群而不影响现有的应用程序。新metadata_cache插件为Innodb 集群提供了透明的客户端连接路由、负载平衡和故障转移的能力。简单易用的MySQL shell
MySQL Shell为所有MySQL相关的任务提供了一个直观、灵活、功能强大的接口。
新的adminapi使得它很容易用一种自我描述的自然语言来创建,监控和管理包括MySQL Router在内的MySQL InnoDB集群,而不需要了解低层次的概念,配置选项,或其他复杂的方面。
原理
MySQL InnoDB集群提供了一个集成的,本地的,HA解决方案。Mysq Innodb Cluster是利用组复制的 pxos 协议,保障数据一致性,组复制支持单主模式和多主模式。
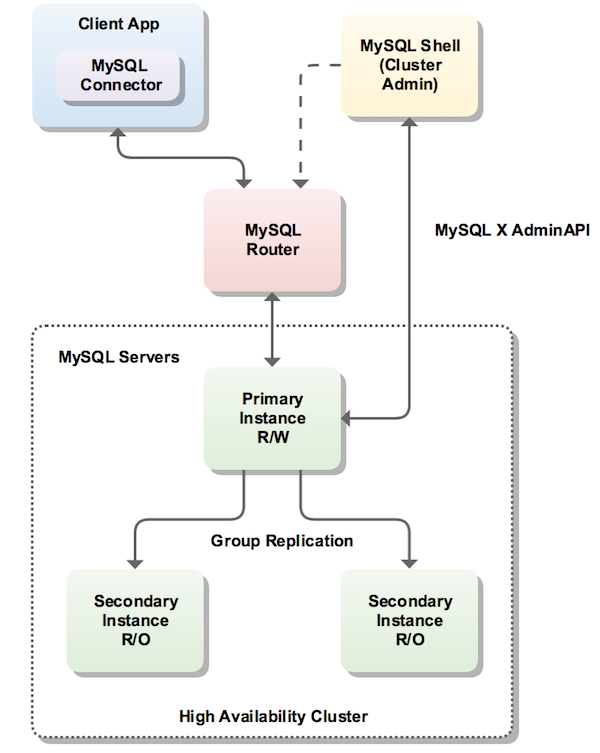
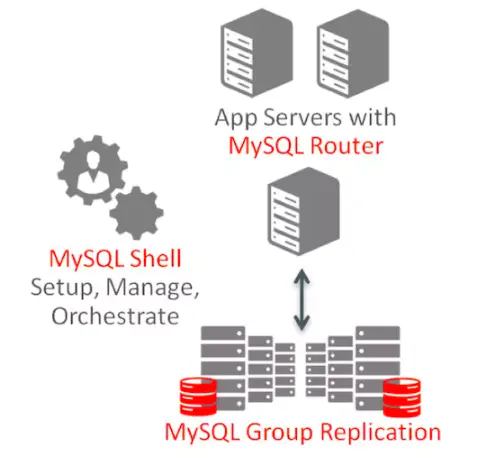
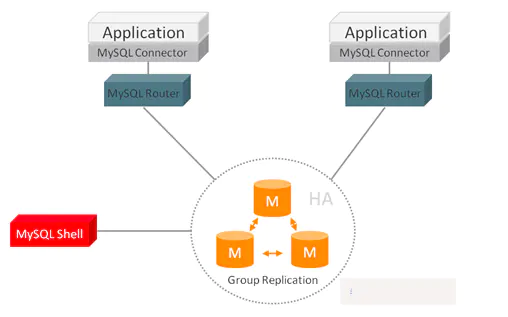
MySQL InnoDB集群由以下几部分组成:
- MySQL Servers with Group Replication:向集群的所有成员复制数据,同时提供容错、自动故障转移和弹性。MySQL Server 5.7.17或更高的版本。
- MySQL Router:确保客户端请求是负载平衡的,并在任何数据库故障时路由到正确的服务器。MySQL Router 2.1.3或更高的版本。
- MySQL Shell:通过内置的管理API创建及管理Innodb集群。MySQL Shell 1.0.9或更高的版本。
各个组件的关系和工作流程如下:
本例安装拓扑
| host | ip | port | server_id | base_dir | data | mysql-shell |
|---|---|---|---|---|---|---|
| node1 | 192.168.1.232 | 3306 | 1 | /opt/mysql-8.0.18 | /data/mysql8.0.18/mysql | /opt/mysql-shell |
| node2 | 192.168.1.233 | 3306 | 2 | /opt/mysql-8.0.18 | /data/mysql8.0.18/mysql | /opt/mysql-shell |
| node3 | 192.168.1.234 | 3306 | 3 | /opt/mysql-8.0.18 | /data/mysql8.0.18/mysql | /opt/mysql-shell |
| node4 | 192.168.1.235 | /opt/mysql-router |
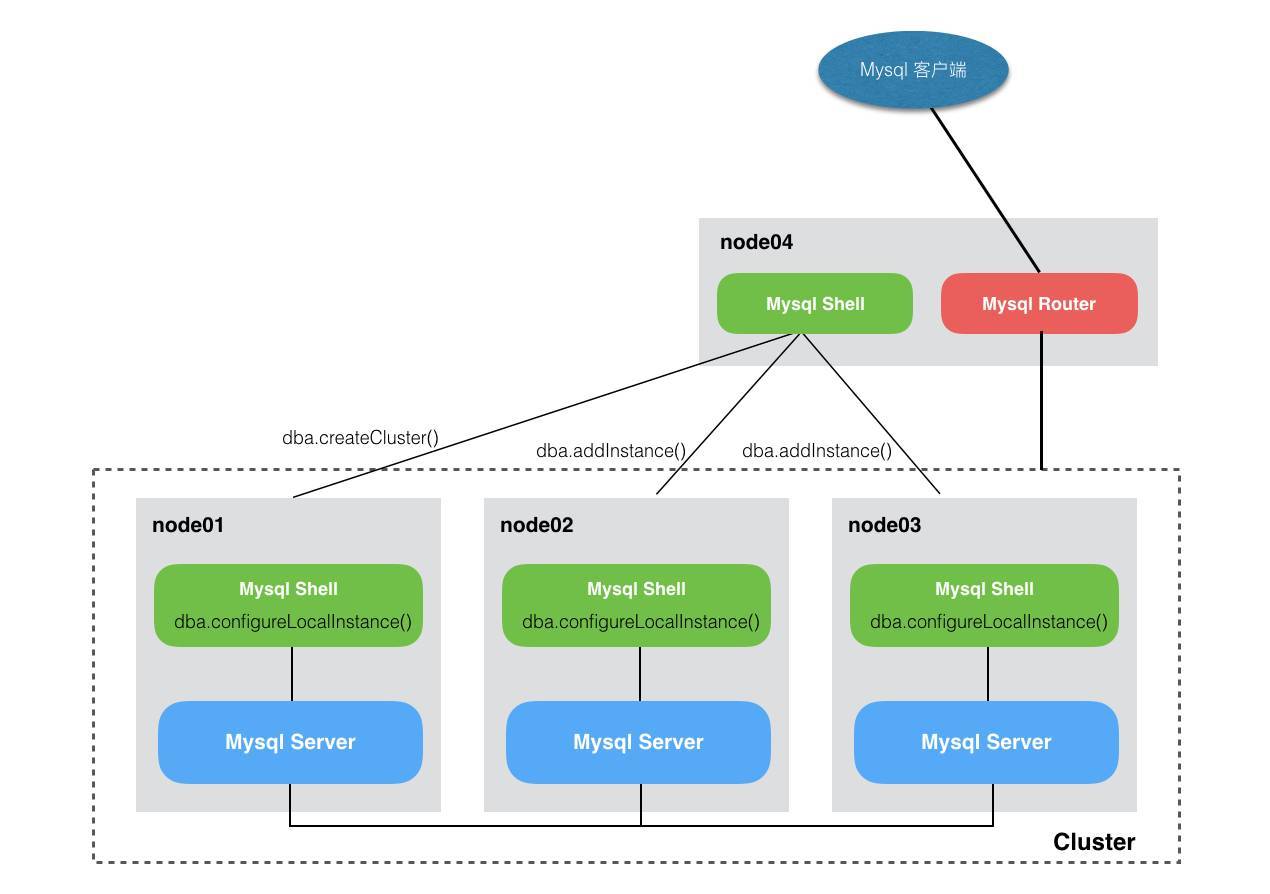
安装
mysql
在节点node1、node2、node3安装mysql可以参考上一篇CentOS 7.6单机配置组复制(MySql Group Replication) | 57°极客闷骚中数据库安装及初始化部分,此处不再叙述。
mysql-shell
在节点node1、node2、node3、node4安装mysql-shell
1 | |
mysql-router
在节点node4安装mysql-router
1 | |
本次因使用虚拟机进行配置安装,所以节点node1安装完毕后可以直接复制另外两个节点:node2,node3。
配置数据库并启动
在节点node1上执行:
修改配置文件
1 | |
启动数据库
1 | |
设置用户
1 | |
mysql-shell配置管理集群
MySQL Shell是一个统一的命令行客户端,使用它可以对MySQL进行管理和操作。它支持多种语言,包括JavaScript,Python和SQL,并且支持编写脚本。此外,它同时支持文档型和关系型数据库模式,并且具有完整的开发和管理API。
看到这里,您可能会发现MySQL Shell与传统的MySQL数据库的客户端mysql的区别了,旧的mysql客户端缺失了脚本功能(可能有人会说可以通过编写SQL命令进行批处理),但是想要通过脚本语言对数据库进行管理的用户会发现,并没有专门适用于合并脚本语言的工具,MySQL Shell的出现弥补了这一点。
使用MySQL Shell除了可以对数据库里的数据进行操作,还可以对数据库进行管理,特别是对Innodb Cluster的支持,使用它可以十分方便的对Innodb Cluster进行管理,配置。您可以理解为MySQL Shell就是为Innodb Cluster 而生的
有关mysql-shell的使用可参考:MySQL家族”新”成员——MySQL Shell - 简书
在节点node1上配置本地实例,为创建集群做准备:
1 | |
在总监节点node4上使用mysql-shell连接node1创建集群(当然也可以直接在node1上操作)
1 | |
添加节点node2,node3
1 | |
mysql-router配置管理
MySQL Router作为InnoDB Cluster(MySQL 7.X)的一部分,它是一个轻量级的中间,可以在Application与下游的MySQL Server之间提供透明的路由方式,它主要用以解决数据库主从库集群的高可用、易于扩展性等。
MySQL Router可以脱离InnoDB Cluster而单独实施,即MySQL 5.6等版本数据库仍然可以使用Router作为其中间代理层。
Router核心原理
1、Router作为一个流量转发层,它的架构层面,位于Application与MySQL Servers之间。
2、其功能角色,类似于Nginx、LVS等,MySQL Servers作为Router的“upstream”(NAT模式);Application不再直连MySQL Servers,而是与Router相连。根据Router的配置,将会把应用程序的READ、WRITE请求转发给下游的MySQL Servers。
3、当下游有多个MySQL Servers,无论主、从,那么它可以对READ、WRITE请求进行负载均衡。(loadbalance)
4、当下游某个Server失效时,Router可以将其从Active列表中移除,当其online后再次加入Active列表,即提供了Failover特性。
5、当MySQL Servers集群拓扑变更时,比如增减Slaves节点,我们只需要修改Router的配置即可,无需修改Application中JDBC URL配置,因为Application配置的为Router地址而非MySQL Servers的原始地址;即“数据库集群迁移”对Application是透明的。
6、Router支持集中式部署,即一个Group通常有多个Router节点,但是MySQL官方并没有提供集群的HA,即Router每个节点均为独立,它们之间互不通信,无Leader角色,无选举机制。那么当某个Router节点失效,Application层面需要借助MySQL Connector的高级特性,比如:failover、loadbalance等协议来实现Failover功能。简单而言,Router中间件与Connector的高级协议互相协作,才能够实现请求在Router集群之间的负载均衡、Failover等。
7、Router中间件,本身不会对请求“拆包”(unpackage),所以我们无法在Router中间件上实现比如“SQL审计”、“隔离”、“限流”、“分库分表”等。但是Router提供了plugin机制,你可以开发自己的plugin来扩展Router的额外特性。(C语言)
8、如果你的MySQL Servers为5.7+版本,且构建为InnoDB Cluster模式,那么Router还能基于metaCache(metaServers)机制,感知MySQL Servers的主从切换、从库增减等集群拓扑变更,而且基于变更能够实现Master自动切换、Slaves列表自动装配等。比如Master失效后,Cluster将会自动选举一个新的Master,此时Router不需要任何调整、可以自动发现此新Master进而继续为Application服务。
9、考虑到Router集中式部署可能引入“额外的部署成本”、“性能降级”、“连接数上限”等问题,我们通常建议大家基于“Agent”方式部署,即部署在Application宿主机器上,潜在的问题就是自动化运维设施需要即备。
10、Router通常是解决“MySQL集群规模性迁移”:比如跨机房部署、流量迁移、异构兼容,或者解决MySQL集群规模性宕机时快速切换等。如果仅仅是为了解决日常的节点增减、读写分离、Failover等,我们仍然建议使用mysql-connector-j支持的“replication”、“loadbalance”协议来实现,基于客户端,而且轻量级。
Router目前已知“局限性”
1、不支持比如“分库分表”、“SQL审计”等。
2、在非InnoDB Cluster架构模式下,如果主从库拓扑变更,需要手动修改Router配置。且Router不支持“reload”,修改配置后需要重启,这在一定程度上会影响Application的服务可用性。但是Router的重启非常快,我们通过验证,通常在秒级别。(5S)。
3、MySQL Router非常轻量级,与直连Servers相比,其性能损耗低于1%,我们通过压力测试,100W读写请求总耗时只增长了200多秒。不过摆在Router面前的问题,就是其对链接数的支撑能力,原则上我们一个Router节点限定在500个TCP链接。Router本身CPU、内存、磁盘消耗都极低,但是我们要求Router节点对网络IO的支撑能力应该较强,考虑到Router底层为“异步IO”,如果条件允许,我们应该构建在较高版本的Linux平台下,且给予合理的CPU资源。(目前我们线上为8Core、16G,万兆网卡)。 备注:MySQL Router在2.1.4版本以下,内核基于select() IO模型,存在连接数500上限、较大SQL请求导致CPU过高,以及并发连接过高时Router假死等问题,建议升级到2.1.6+。
4、Router对连接的管理是基于“粘性”方式,即Application与Router的一个TCP连接,将对应一个Router与MySQL Server的连接,当Application与Router的连接失效时,Router也将断开其与MySQL Server的连接;只要Router上下游网络联通性正常,那么Router将不会主动断开与Application的连接,也不会切换其与Server的连接。即当Application与Router创建一个新连接时,Router将根据负载均衡算法,选择一个Server并与其建立连接,此后将唯一绑定,直到此Server失效时触发重新选择其他Server。
这就引入一个问题,如果某个连接上发生了“繁重”的SQL操作,那么将会导致下游Server伴随高负载而无法“负载均衡”,或许这就是基于TCP NAT代理模式的通病吧。比较有幸的是,我们通常使用DataSource Pool,且MySQL Connector在面对这样的问题时,也有相应的解决办法。
5、不能设定权重,即按照权重负载均衡。
默认路由策略说明
1、对于read-write模式:将采用“首个可用”算法,优先使用第一个server,当第一个server(即3306)不可达时,将会Failover到第二个server(3307);依次进行。如果都不可达,那么此端口上的请求将会被中断,不可用,且此时Router将不可用(主要是此port将不能服务)。(需要注意,此算法只遍历一次列表,即逐个验证destinations中的Server,不会循环)。
特别注意,一旦所有的Servers依次验证且不可用后,Router将不能继续服务,内存状态设定为aborted,即使此后Servers恢复上线,也不能继续对Client提供服务,因为它不会与Servers保持心跳检测;对于Router而言,直接拒绝Client连接请求,只有重启Router节点才能解决。
2、对于read-only模式:将采用“轮询”算法,依次选择server新建连接,如果某个Server不可达,将会重试下一个Server,如果所有的Server都不可达,那么此端口上的请求将中断,即READ操作将不可用。同时Router将会持续与每个Server保持心跳探测,当恢复后重新加入Active列表,此后那些新建连接请求将可以分发给此Server。
引导mysql-router
1 | |
启动mysql-router
1 | |
测试读写分离
1 | |
测试高可用性
1 | |
问题
Dba.getCluster: This function is not available through a session to a standalone instance (RuntimeError) 说明集群中的主节点已经不在该机器上,查询后更改机器重试一下即可;
参考
20.4 在InnoDB集群中工作 - 知乎
Mysql Router核心原理及优缺点总结 - 知乎
MySQL Router - williamzheng - 博客园
Mysql Innodb cluster集群搭建 - 简书
MySQL InnoDB Cluster 详解 - 简书
Mysql 高可用 InnoDB Cluster 多节点搭建过程 - 云+社区 - 腾讯云
官方工具|MySQL Router高可用原理与实战 - 51CTO.COM