转:MySQL crash recovery
数据恢复的起点与终点
crash recovery 用于实现 crash-safe,简单了解下 crash recovery 的原理。
1 提出问题
1、每次启动时都需要 crash recovery 吗?
2、Log scan progressed past the checkpoint lsn 是哪个 LSN?
3、如何判断是否是异常关闭?
4、恢复的起点与终点分别是什么?
5、每个 page 都需要判断吗?
6、数据库正常关闭时会做什么?
。。。
2 相关知识
2.1 脏页 & 刷脏
buffer pool 可以提高读请求性能,其中维护 LRU 链表用于管理内存页。
当内存页(buffer pool)与磁盘数据不一致时,将该内存页称为脏页,而将内存页数据刷到磁盘的操作称为刷脏(flush)。
As changes are made to data pages that are cached in the buffer pool, those changes are written to the data files sometime later, a process known as flushing.
与 crash recovery 有关的脏数据包括内存中的脏数据页与脏日志(redo log)。
其中数据的单位是页(page),redo log 的单位是块(block)。
2.2 redo log
2.2.1 WAL
redo log 是 InnoDB 存储引擎特有的物理日志,用于实现 crash-safe。
crash-safe 指的是 InnoDB 可以保证即使数据库或服务器发生异常重启,之前提交的记录都不会丢失。
redo log 基于 WAL(Write-Ahead Logging)技术实现。
WAL 的核心是先写日志,后写磁盘。InnoDB 通常在系统比较空闲的时候,将操作记录更新到磁盘中。
崩溃恢复时,内存中脏页丢失,通过 redo log 进行恢复。
InnoDB 如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让 redo log 更新内存内容。更新完成后,内存页变成脏页,最终由后台线程完成刷脏。
可见 redo log 恢复数据的原理是 redo log + 数据页,因此要求数据页是完整的、正确的。
由于数据页的大小(默认 16K)大于文件系统 IO 的最小单位(4K),因此可能出现部分页写入(partial page write)。
因此引入 doublewrite buffer 用于解决该问题,原理是在刷脏之前将脏页顺序写入 doublewrite buffer,并将副本持久化存储。
redo log 不需要 doublewrite 的支持,原因是 redo log 写入的单位就是 512 字节,也就是磁盘 IO 的最小单位,所以无所谓数据损坏,同时写入效率高。
IO 的最小单位:
1)数据库 IO(页,page)的最小单位是 16K(MySQL 默认,oracle 是 8K)
2)文件系统 IO(块,block)的最小单位是 4K(也有 1K 的)
3)磁盘 IO(扇区)的最小单位是 512 字节
2.3 checkpoint
2.3.1 概念
思考一下这个场景:如果 redo log 可以无限地增大,同时缓冲池也足够大,那么是不需要将缓冲池中页的新版本刷新回磁盘。因为当发生宕机时,完全可以通过 redo log 来恢复整个数据库系统中的数据到宕机发生的时刻。
但是这需要两个前提条件:
1)缓冲池可以缓存数据库中所有的数据;
2)redo log 可以无限增大。
当然,这是不合理的。因此引入 checkpoint(检查点)作为数据刷盘的规则。
The checkpoint is a record of the latest changes (represented by an LSN value) that have been successfully written to the data files.
用于解决以下几个问题:
1)缩短数据库的恢复时间
当数据库发生宕机时,数据库不需要重做所有的日志,因为 checkpoint 之前的页都已经刷新回磁盘。数据库只需对 checkpoint 后的 redo log 进行恢复,这样就大大缩短了恢复的时间。
2)缓冲池不够用时,将脏页刷新到磁盘
只要将 buffer pool 中的某些页面刷入到磁盘中,其对应的日志就失效了,进而可以被覆盖,因此 redo log 循环写入。
简而言之,通过 checkpoint 机制保证检查点之前的数据落盘,使对应的日志失效,直接覆盖不会导致数据不完整、数据丢失等问题。
3)redo log 不可用时,刷新脏页
涉及 LSN,详见下文中 Async/Sync Flush Checkpoint。
2.3.2 分类
1)Sharp Checkpoint(全量)
innodb_fast_shutdown 参数用于控制数据库正常关闭时是否将所有的脏页写入磁盘,默认为 1,表示数据库关闭时需要 flush dirty page。
2)Fuzzy Checkpoint(部分)
数据库运行过程中使用 Sharp Checkpoint 的话,会影响数据库的可用性。
因此运行过程中使用 Fuzzy Checkpoint 进行刷脏。
以下几种情况会触发 Fuzzy Checkpoint:
- Master Thread Checkpoint,系统空闲时异步刷新,每秒或每 10 秒从缓冲池脏页列表刷新一定比例的页回磁盘;
- FLUSH_LRU_LIST Checkpoint,空闲页不足时,根据 LRU 算法,淘汰列表尾部的页,如果这些页中有脏页,需要进行 checkpoint。通过 innodb_lru_scan_dept 参数控制 LRU 列表中可用页的数量,默认为 1024;
- Async/Sync Flush Checkpoint,redo log 写满时,MySQL 会停止所有更新操作,不会阻塞查询操作,将脏页强制刷到磁盘。包括同步刷盘(90%)与异步刷盘(75%);
- Dirty Page too much Checkpoint,脏页过多时,将脏页强制刷到磁盘。通过 innodb_max_dirty_pages_pct 参数控制阈值,默认为 75%。
2.4 LSN
checkpoint 通过 LSN 保存记录。
2.4.1 概念
在 InnoDB 内部的日志管理中,LSN(Log Sequence Number,日志逻辑序列号)用于精确记录日志位置信息。
LSN 是 8 字节大小的数字,且单调递增,表示事务写入到日志的字节总量,对应 redo log 的一个个写入点。每次写入长度为 length 的 redo log, LSN 的值就会加上 length。
LSN
This arbitrary, ever-increasing value represents a point in time corresponding to operations recorded in the redo log. (This point in time is regardless of transaction boundaries; it can fall in the middle of one or more transactions.)
It is used internally by InnoDB during crash recovery and for managing the buffer pool.
LSN 用于关联 dirty page 与 redo log,类似于 XID 用于关联 redo log 与 binlog。
实际上,每个页有 LSN,redo log 有 LSN,checkpoint 也有 LSN。
2.4.2 page LSN
page 的 File Header 头信息中 FIL_PAGE_LSN 字段用于实现 redo log 重放时的幂等性。
page 在修改时,会将对应的 redo log 记录的 LSN 记录在 page 的 FIL_PAGE_LSN 字段。
在奔溃恢复应用日志阶段,如果 redo log 的 LSN 小于等于这个值,就不需要再次应用 redo log 了,而如果 redo log 的 LSN 大于这个值,将跳过已经应用的 redo log,从而实现重放的幂等性。
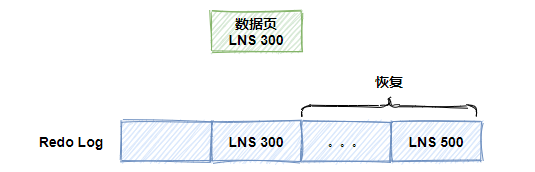
如下图所示,假设 redo log 的 LSN 是 500,数据页的 LSN 是 300,表明重启前有部分数据未完全刷入到磁盘中,那么系统则将 redo log 中 LSN 序号 300 到 500 的记录进行重放刷盘。
2.4.3 redo log LSN
如下图所示,redo log 固定大小,顺时针循环写入。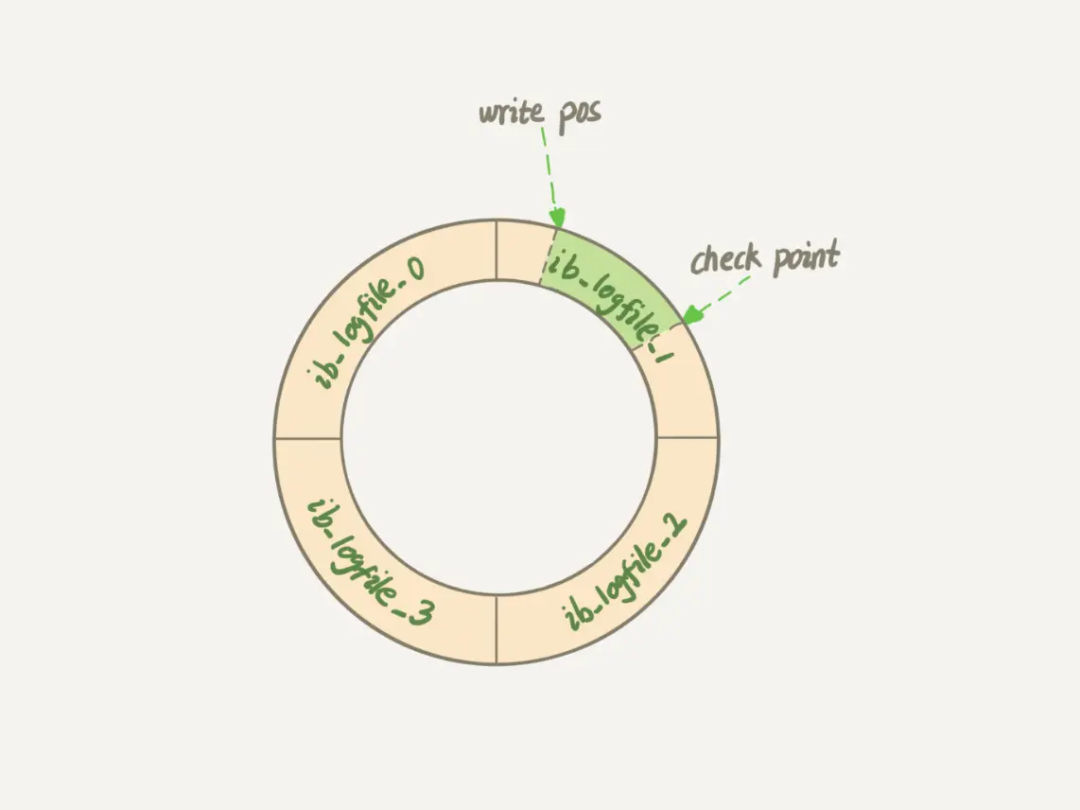
其中:
write pos 是当前日志记录的位置(Log flushed up),一边写一边后移;
check point 当前要擦出的位置(Last checkpoint at),表示 redo log 的记录中这个 LSN 之前的数据已经全部落盘,循环往后递增,擦除记录前要把记录更新到数据文件。
2.4.4 checkpoint LSN
buffer pool 中的脏页刷盘时,从 flush list 尾部开始将数据页 fsync 到磁盘,并把最后一页的 LSN 记为 last checkpoint LSN,写入到 redo log 的头部。
此外,InnoDB 的 master 线程大约每隔 10 秒会做一次 redo checkpoint,此时只会把 flush list 中最老的 LSN 写入到 redo log 头部,并不会刷脏页(相当于仅移动 redo checkpoint)。
checkpoint 信息被写入到了第一个 iblogfile 的头部,但写入的文件偏移位置比较有意思,当
log_sys->next_checkpoint_no 为奇数时,写入到 LOG_CHECKPOINT_2(3 *512 字节)位置,为偶数时,写入到 LOG_CHECKPOINT_1(512 字节)位置。
在 crash recovery 过程中,将读取记录在 checkpoint 中的 LSN 信息,并取两者的最大值作为起点,然后从该 LSN 开始扫描 redo log。2.4.5 log record 生命周期
InnoDB 中 log record 的生命周期中包括以下四种 LSN:
Log sequence number(LSN1),内存中 redo log 的 LSN,是整个数据库最新的 LSN 值;
Log flushed up(LSN2),磁盘中 redo log 的 LSN,崩溃恢复的终点;
Pages flushed up(LSN3),磁盘中数据页的 LSN;
Last checkpoint at(LSN4),redo log checkpoint 的 LSN,崩溃恢复的起点。
通常这 4 个 LSN 是递减的,即:LSN1>=LSN2>=LSN3>=LSN4。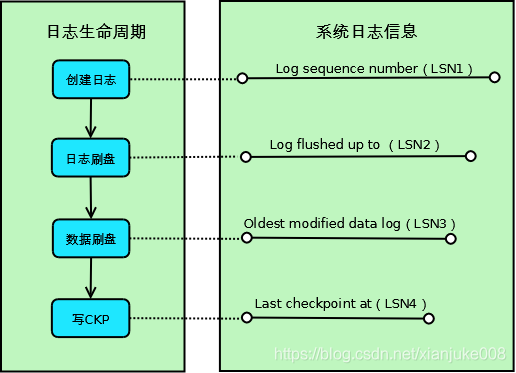
如下所示,通过 show engine innodb status 命令返回信息中 LOG 模块中可以查看 LSN 号。1
2
3
4
5
6
7mysql> show engine innodb status \G
Log sequence number 3155826224010
Log flushed up to 3155826224010
Pages flushed up to 3155826221704
Last checkpoint at 3155826221528
0 pending log flushes, 0 pending chkp writes
541100647 log i/o's done, 3.45 log i/o's/second
四种 LSN 的关系如下图所示。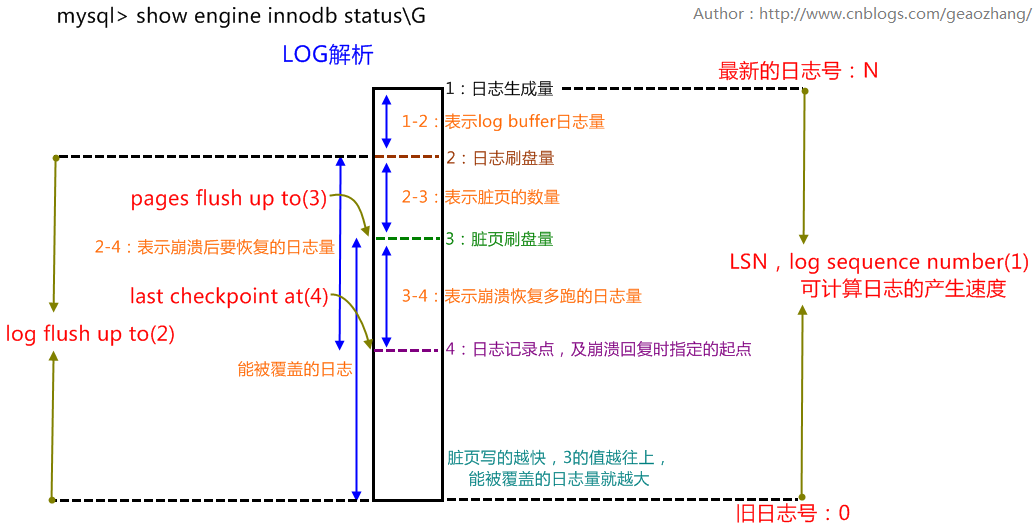
其中 Log flushed up(LSN2)是崩溃恢复的终点,Last checkpoint at(LSN4)是崩溃恢复的起点。
crash recovery 时,从 Last checkpoint at 扫描 redo log 直到 Log flushed up,然后 apply redo log 到 buffer pool 中的 page。
3 案例
3.1 正常关闭
3.1.1 案例 1
如下所示,正常关闭数据库后再次启动时,查看错误日志。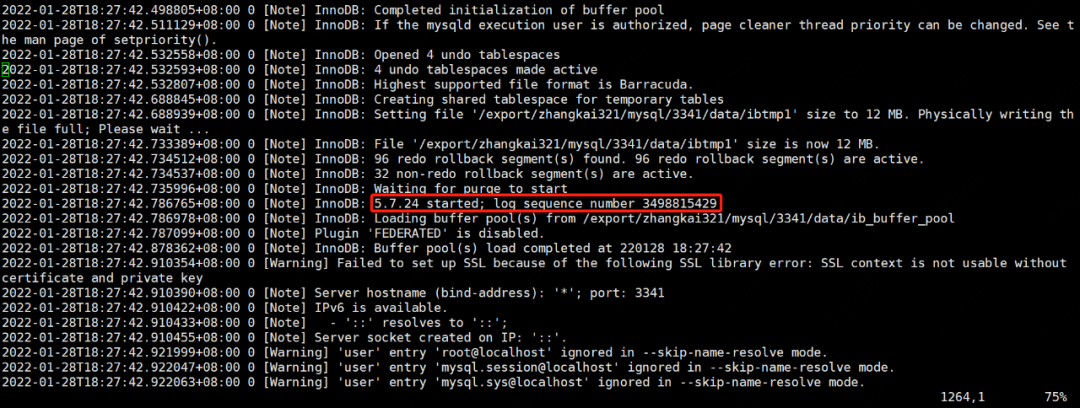
其中:
- InnoDB: 5.7.24 started; log sequence number 3498815429
表明数据库正常关闭。
如下所示,数据库关闭时打印日志。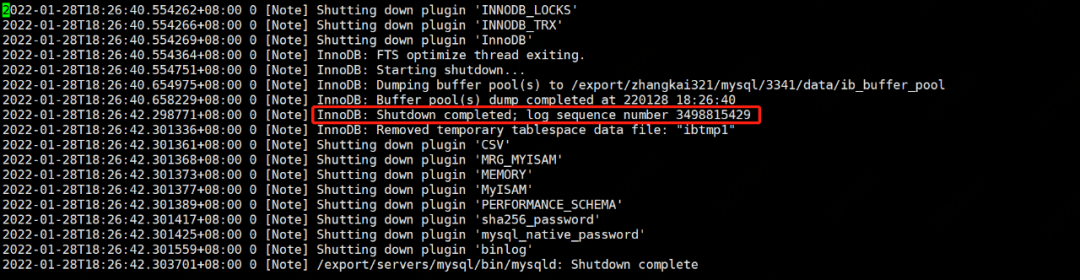
其中: - InnoDB: Shutdown completed; log sequence number 3498815429
实际上,当数据库正常关闭时,所有 buffer pool 里面的脏页都会刷新到磁盘中,同时记录最新 LSN 到 ibdata 文件的第一个 page 中。
3.2 异常关闭
3.2.1 案例 1
如下所示,是一个 crash recovery 案例。
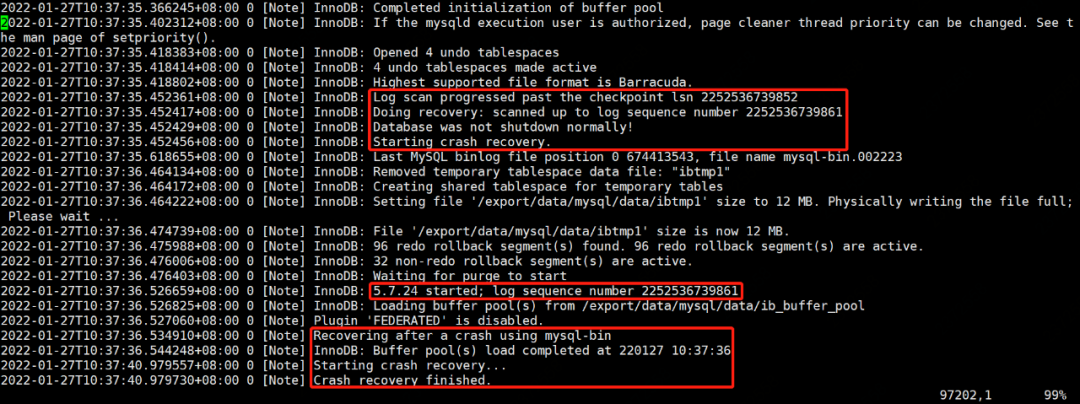
其中:
- InnoDB: Log scan progressed past the checkpoint lsn 2252536739852
崩溃恢复的起点
InnoDB: Doing recovery: scanned up to log sequence number 2252536739861
扫描 redo logInnoDB: Database was not shutdown normally!
表明数据库异常关闭InnoDB: Starting crash recovery
开始崩溃恢复3.2.2 案例 2
首先,从错误日志中可以明显看到,Database was not shutdown normally,表明数据库异常关闭。
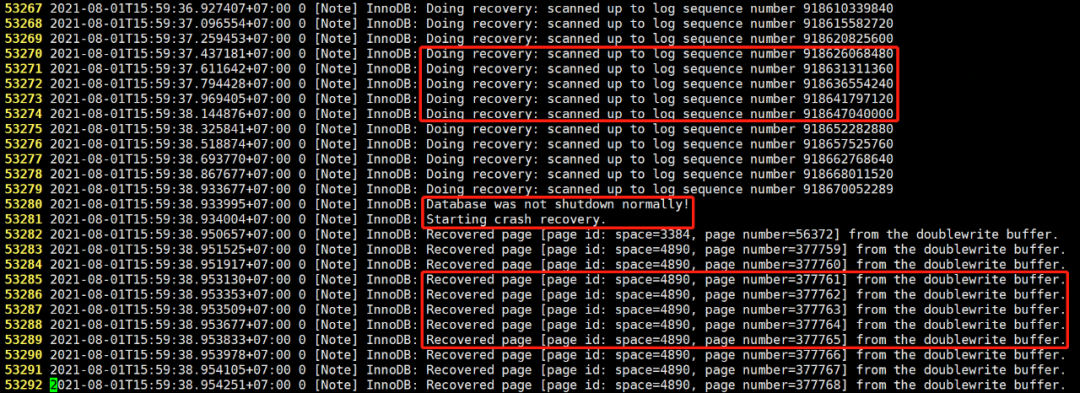
与案例 1 的区别在于使用到了 doublewrite buffer。
表明异常关闭时出现部分页写入,而基于 redo log 恢复要求 page 完整。
因此在 redo log 加载到内存以后,从 doublewrite buffer 中加载数据页的一个最近的副本,将其复制到表空间文件,用于应用 redo log。
If there’s a partial page write to the doublewrite buffer itself, the original page will still be on disk in its real location.
When InnoDB recovers, it will use the original page instead of the corrupted copy in the doublewrite buffer. However, if the doublewrite buffer succeeds and the write to the page’s real location fails, InnoDB will use the copy in the doublewrite buffer during recovery.
4 回答问题
4.1 每次启动时都需要 crash recovery 吗?
是的,每次数据库启动时都会进行 crash recovery 操作,这是常规启动的一步。
1 | |
MySQL 每次启动时,都会进行恢复操作。
如下图所示,具体包括两个阶段性操作:redo log 处理、undo log 及 binlog 处理。
本文中暂未介绍 undo log 及 binlog 处理。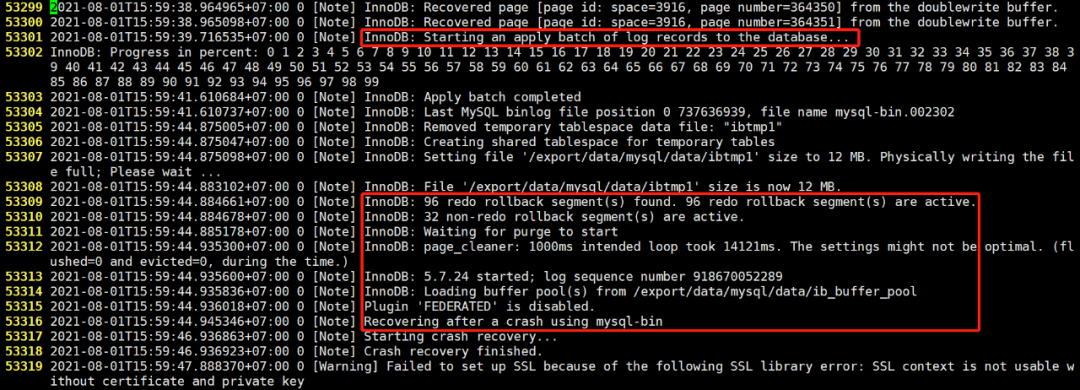
4.2 Log scan progressed past the checkpoint lsn 是哪个 LSN?
打印日志 InnoDB: Log scan progressed past the checkpoint lsn,其中的 LSN 等于第一个 redo log 文件头的 checkpoint LSN。
相关逻辑没看明白,待办。
1 | |
对比正常关闭与异常关闭的打印日志,正常关闭时打印 log sequence number。
此外,每条打印日志中扫描 redo log 时新增的 LSN 相同,原因是什么呢?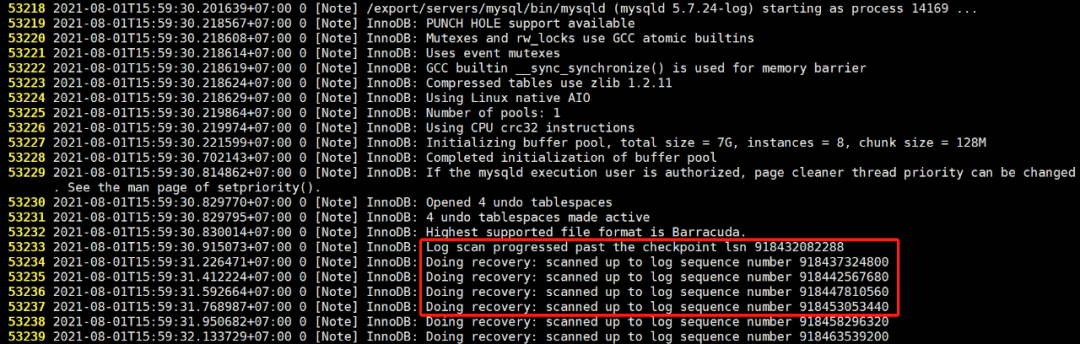
原因是当扫描结束或每扫描 80 次时打印一次日志,即 InnoDB: Doing recovery: scanned up to log sequence number。
1 | |
从日志中随机计算两个相邻 LSN 的差值,结果等于 5M。
每次读取 RECV_SCAN_SIZE(宏定义:4)个日志 pages,即 64KB。
因此除以 64KB,结果等于 80,表明扫描了 80 次。
1 | |
4.3 如何判断是否是异常关闭?
正常关闭时 checkpoint_lsn 等于 flush_lsn,异常关闭时两者不等,则判定需要进行 crash recovery。
1 | |
checkpoint_lsn 等于 redo 中第一个 redo record 的 LSN,而 flush_lsn 是什么呢?
数据库启动时,会打开系统表空间 ibdata,并读取存储在其中的 LSN:
1 | |
上述调用将从 ibdata 中读取的 LSN 存储到变量 flushed_lsn 中,表示上次 shutdown 时的 checkpoint 点,在后面做崩溃恢复时会用到。另外这里也会将 double write buffer 内存储的 page 载入到内存中(buf_dblwr_init_or_load_pages),如果 ibdata 的第一个 page 损坏了,就从 dblwr 中恢复出来。
继续上面的逻辑,判断为异常关闭后将修改标志位。
1 | |
然后对涉及的表空间进行初始化处理,至于如何判断涉及的表空间详见下文中每个 page 都需要判断吗。
1 | |
其中打印日志 Database was not shutdown normally!。
1 | |
4.4 恢复的起点与终点分别是什么?
上文中提到,Log flushed up(LSN2)是崩溃恢复的终点,Last checkpoint at(LSN4)是崩溃恢复的起点。
crash recovery 时,从 Last checkpoint at(第一个 redo log 文件头的 checkpoint LSN)扫描 redo log 直到 Log flushed up,生成哈希表 recv_sys->addr_hash,然后 apply redo log 到 buffer pool 中的 page。
哈希表的 key 是 (space_id, page_no),value 是数据页链表,将相同页上的变更作为链表节点链在一起。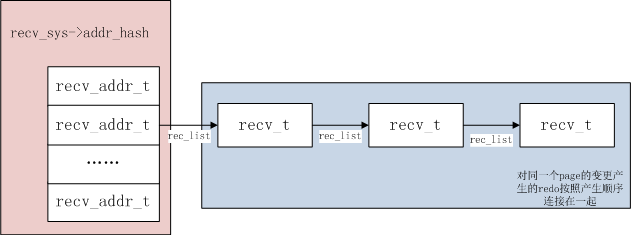
如下所示,循环读取 64KB(RECV_SCAN_SIZE)日志到 log_sys->buf 中,然后调用 recv_scan_log_recs 函数以 block(512 字节)为单位循环处理日志块,并将日志解析的结果添加到哈希表中。当 redo log 扫描并解析完成后,将 addr_hash 中的 log 应用到对应的 page 上。
1 | |
4.5 每个 page 都需要判断吗?
崩溃恢复时,内存中脏页丢失,通过 redo log 进行恢复。
InnoDB 如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让 redo log 更新内存内容。更新完成后,内存页变成脏页,最终由后台线程完成刷脏。
那么,每个 page 都需要判断吗?
实际上不是的,原因是 MySQL 5.7 版本中可以判断出受影响的表空间。
MySQL 5.7 版本以前,需要扫描所有的数据文件,读取第一个数据页获取表空间 ID,以此建立 space 和 filepath 的映射关系。
Redo-log-based discovery, introduced in MySQL 5.7, replaces directory scans that were used in earlier MySQL releases to construct a “space ID-to-tablespace file name” map that was required to apply redo logs.
MySQL 5.7 版本中引入 Tablespace Discovery During Crash Recovery,用于识别受影响的表空间,而只有这些受影响的表空间才需要 redo log application。
Tablespace discovery is the process that InnoDB uses to identify tablespaces that require redo log application.
If, during recovery, InnoDB encounters redo logs written since the last checkpoint, the redo logs must be applied to affected tablespaces. The process that identifies affected tablespaces during recovery is referred to as tablespace discovery.
tablespace discovery 具体是怎么做的呢?
首先,打开系统表空间 ibdata,读取第一个 page 中的 LSN,若第一个页损坏,则从 double write buffer 中进行恢复,这个 LSN 就是上次 shutdown 时的 checkpoint 点。
然后,进入 redo log 文件,读取第一个 redo log 文件头的 checkpoint LSN, 并根据该 LSN 定位到 redo log 文件中对应的位置。从 last checkpoint 开始扫描 redo log 直到日志末尾,查找在修改表空间页面时写入的 MLOG_FILE_NAME 记录。MLOG_FILE_NAME 记录中包含表空间 ID 和文件名。
Tablespace discovery is performed by scanning redo logs from the last checkpoint to the end of the log for MLOG_FILE_NAME records that are written when a tablespace page is modified. An MLOG_FILE_NAME record contains the tablespace space ID and file name.
恢复的时候,只需要从 last checkpoint 往后扫描到 MLOG_CHECKPOINT 的位置,这样就能获取到需要恢复的 space 和 filepath,在恢复过程中,只需要打开这些 ibd 文件即可,当然由于 space 和 filepath 的对应关系通过 redo 存了下来,恢复的时候也不再依赖数据字典。
MLOG_CHECKPOINT 的优点是不需要打开额外的文件,缺点是导致系统检查点逻辑与恢复逻辑变得更复杂,并且带来了很多 bug。
4.6 数据库正常关闭时会做什么?
上面提到正常关闭时 checkpoint_lsn 等于 flush_lsn,最终也是通过两者的比较判断是否是异常关闭。
那么,数据库正常关闭时都会做什么呢?
数据库正常关闭时,在 flush redo log 和脏页后,会做一次完全同步的 checkpoint(Sharp Checkpoint),并将最新 checkpint 的 LSN 写入 ibdata 文件的第一个 page 中 File Header 头信息的 FIL_PAGE_FILE_FLUSH_LSN 字段,用于记录在正常 shutdown 时安全 checkpoint 到的点,代表数据页的文件至少被更新到的位置。对于独立表空间,该值始终为 0。
异常关闭时,脏页丢失,同时没有记录最新 LSN 到 ibdata file。
如下所示,正常关闭数据库,错误日志中显示在关闭过程中将记录最新 checkpoint,即 redo log 中的 checkpoint。
因此,正常关闭时 LSN1=LSN2=LSN3=LSN4,即所有的数据页面都已经被刷成了最新的状态。
5 结论
5.1 crash recovery
crash recovery 时,从 Last checkpoint at(第一个 redo log 文件头的 checkpoint LSN)扫描 redo log 直到 Log flushed up,生成哈希表 recv_sys->addr_hash,然后 apply redo log 到 buffer pool 中的 page。
与 crash recovery 有关的内存中脏数据包括内存中的脏数据页与脏日志(redo log)。
两者均需要落盘,对应的 LSN 分别是 Pages flushed up 与 Log flushed up。
此外,还有 redo checkpoint 机制用于保证 redo log 的记录中 Last checkpoint at 之前的数据已经全部落盘,对应的日志可以被覆盖,没有数据丢失的风险。
因此,Log flushed up(LSN2)是崩溃恢复的终点,Last checkpoint at(LSN4)是崩溃恢复的起点。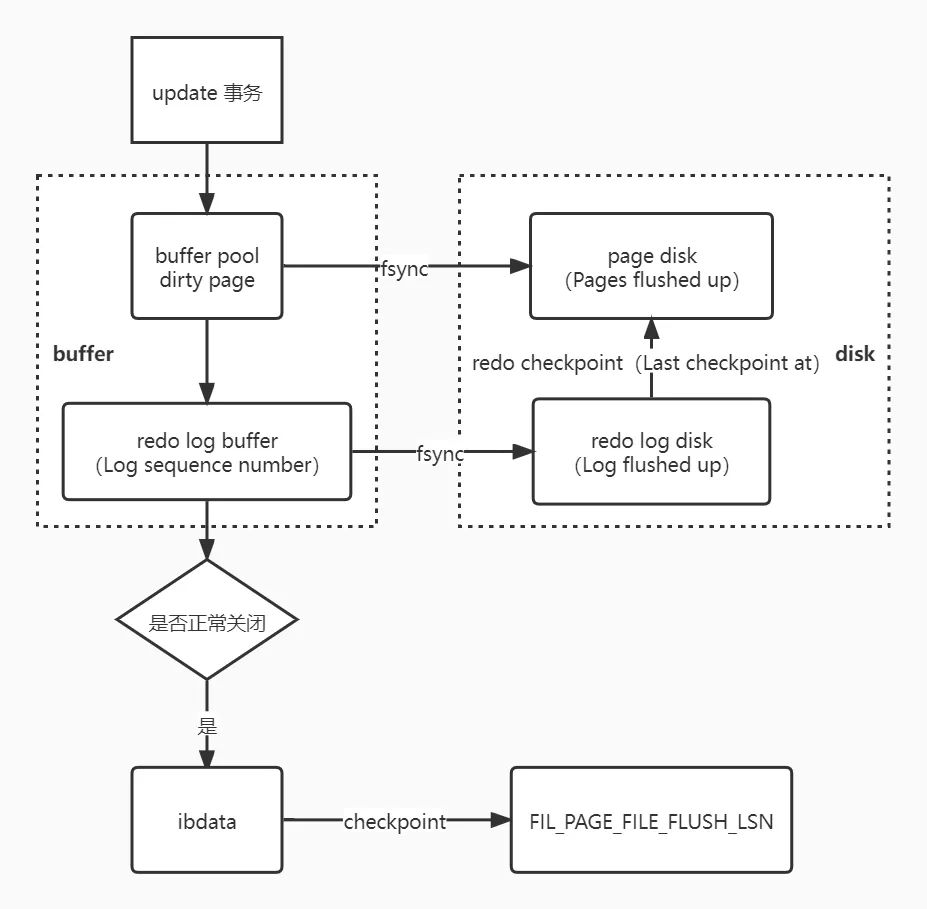
5.2 innodb_flush_log_at_trx_commit
redo log 用于实现 crash-safe,为保证数据不丢失(事务的持久性),需保证 redo log 的完整性。
InnoDB 通过参数 innodb_flush_log_at_trx_commit 控制事务提交时是否强制刷盘,有三种可能取值:
- 0 表示每次事务提交时将 redo log 留在 redo log buffer,由后台线程刷盘。InnoDB 有一个后台线程,每隔 1 秒,将 redo log buffer 中的日志,调用 write 写到文件系统中的 page cache,然后调用 fsync 持久化到磁盘;
- 1 表示每次事务提交时将 redo log 直接持久化到磁盘,默认为 1;
- 2 表示每次事务提交时将 redo log 写到 page cache。该模式下,MySQL 会每秒执行一次 flush 操作。但由于进程调度策略问题,这个 “每秒执行一次 flush 操作” 并不是保证 100% 的 “每秒”。
通常我们说 MySQL 的 “双 1” 配置,指的就是 sync_binlog 和 innodb_flush_log_at_trx_commit 都设置成 1。双 1 适合数据安全性要求非常高,而且磁盘 IO 写能力足够支持业务的场景。
在特殊场景下,可以将线上生产库设置成 “非双 1”。如:
- 有预知的业务高峰期;
- 备库延迟,为了让备库尽快赶上主库;
- 用备份恢复主库的副本,应用 binlog 的过程中;
- 批量导入数据时。
双”1”模式下,当磁盘IO无法满足业务需求时,推荐的做法是 innodb_flush_log_at_trx_commit=2 ,sync_binlog=N (N 为 500 或 1000) ,且使用带蓄电池后备电源的缓存 cache,防止系统断电异常。
不建议把 innodb_flush_log_at_trx_commit 设置成 0。
因为把这个参数设置成 0,表示 redo log 只保存在内存中,每秒持久化到磁盘,这样的话 MySQL 本身异常重启时会丢失 1 秒的数据。
而 redo log 写到文件系统的 page cache 的速度也是很快的,所以将这个参数设置成 2 跟设置成 0 其实性能差不多,但这样做 MySQL 异常重启时就不会丢数据了,相比之下风险会更小,原因是操作系统的缓存没有丢失。服务器宕机时,同样也会丢失 1 秒的数据。
5.3 inodb_fast_shutdown
inodb_fast_shutdown 参数用于控制数据库正常关闭时是否将所有的脏页写入磁盘,默认为 1。
该参数有 0、1、2 三个值可以选择:
- 0 表示在 InnoDB 关闭的时候,需要 purge all、merge change buffer、flush dirty pages。这是最慢的一种关闭方式,但是 restart 的时候也是最快的。
- 1 表示在 InnoDB 关闭的时候,它不需要 purge all、merge change buffer,只需要 flush dirty page,在缓冲池中的一些数据脏页会刷新到磁盘。
- 2 表示在 InnoDB 关闭的时候,它不需要 purge all、merge change buffer,也不进行 flush dirty page,只将 log buffer 里面的日志刷新到日志文件 log files,MySQL 下次启动时,会执行恢复操作。
6 待办
- FIL_PAGE_FILE_FLUSH_LSN 与 第一个 redo log 文件头的 checkpoint LSN 的关系
- undo log
- MTR
原文
参考教程
- 梳理下MySQL崩溃恢复过程 - 苏家小萝卜 - 博客园
- 【MySQL document】InnoDB Recovery
- MySQL · 引擎特性 · InnoDB 崩溃恢复过程
- MySQL · 引擎特性 · InnoDB redo log漫游
- 深入浅出InnoDB MLOG CHECKPOINT - 腾讯云开发者社区-腾讯云
- MySQL:Innodb恢复的学习笔记_ITPUB博客
- MySQL:Innodb crash recovery一些代码_ITPUB博客
- 全方位解读 MySQL 日志实现内幕(二) - 墨天轮
- MySQL redo log及recover过程浅析 - 刘浩de技术博客 - 博客园
- MYSQL crash recovery
- 转:InnoDB Crash Recovery 流程源码实现分析 - 春困秋乏夏打盹 - 博客园
- MySQL InnoDB 的redo log与 checkpoint_xianjuke008的博客-CSDN博客
- 02 | 日志系统:一条SQL更新语句是如何执行的?-极客时间
- mysql crash recovery_InnoDB crash recovery 过程和疑问_翼龙飞兔1314的博客-CSDN博客
- MySQL中的redo log和undo log - 墨天轮
- mysql崩溃恢复过程_MySQL崩溃恢复过程常见错误分析_weixin_32445333的博客-CSDN博客
- LSN、Checkpoint?MySQL的崩溃恢复是怎么做的? - 墨天轮